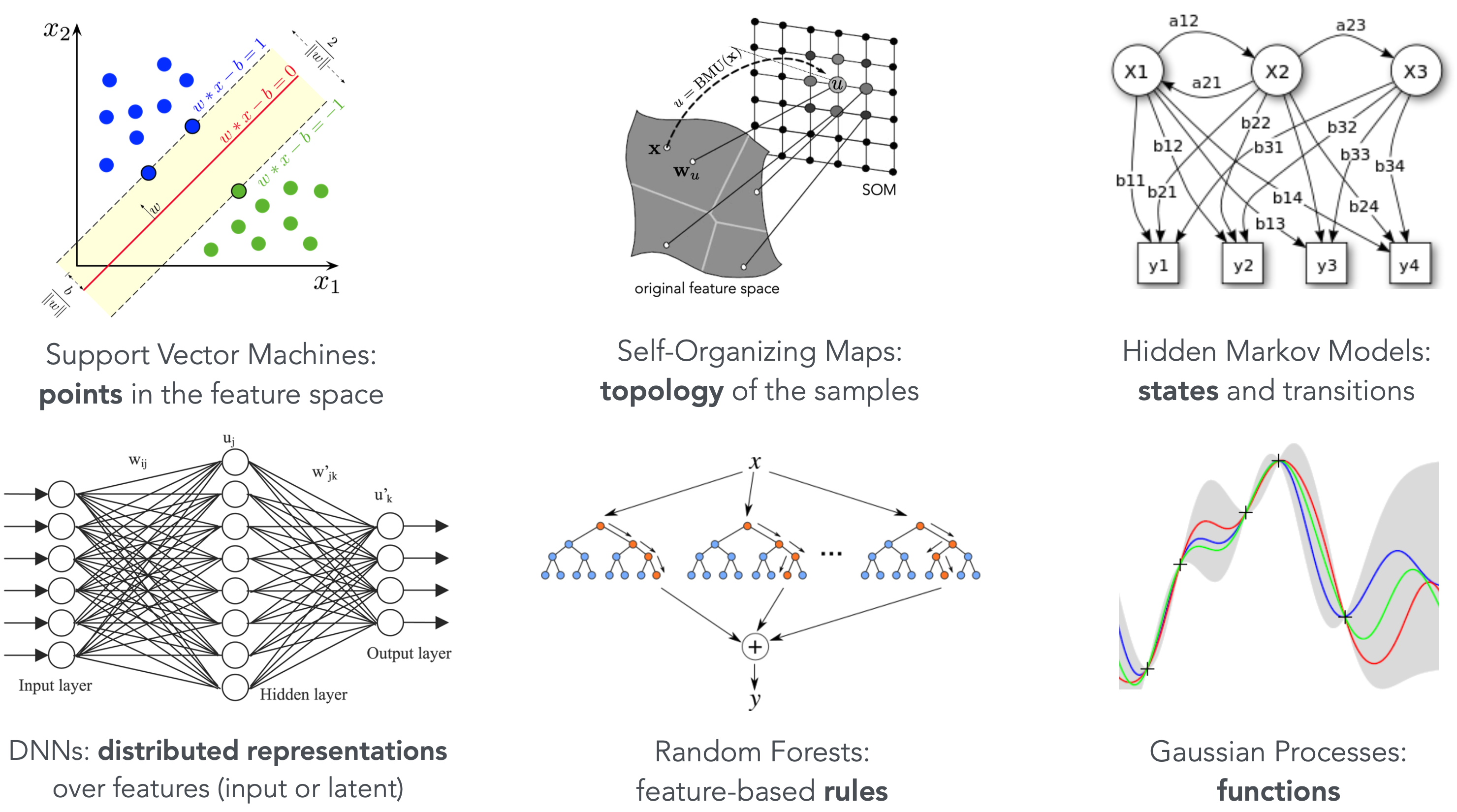
Not all neural data require deep learning, classical machine learning still has a place in knowledge discovery
In this short note we want to make the case for classical (by this we mean non-neural networks) machine learning algorithms can still play an important role in knowledge discovery and modeling.
Deep neural network have huge capacity and expressive power. They are very flexible and given enough data a sufficiently large neural network will find patterns and learn this data. And for most applications that we see around us this is exactly what is needed — as many other fields, neuroscience generates lots of data and application of deep learning models is a logical choice.
However, there is something to be said in favour of the limitations that the classical machine learning algorithms has. It is precisely these limitations that offer something unique to the user. Consider the question of what is the representation of knowledge that a trained machine learning model uses to represent the patterns that it has found in the data. In case of DNNs this is a distributed representation, an embedding, in a highly multidimensional space of network parameters. Which is powerful, but also very hard to interpret or to articulate to a human being.
Classical machine learning algorithms on the other hand each have a very specific representation of the knowledge they have captured. And if this representation is informative to you, then perhaps you should pick the algorithms that is tuned to capture the knowledge in the desired form.
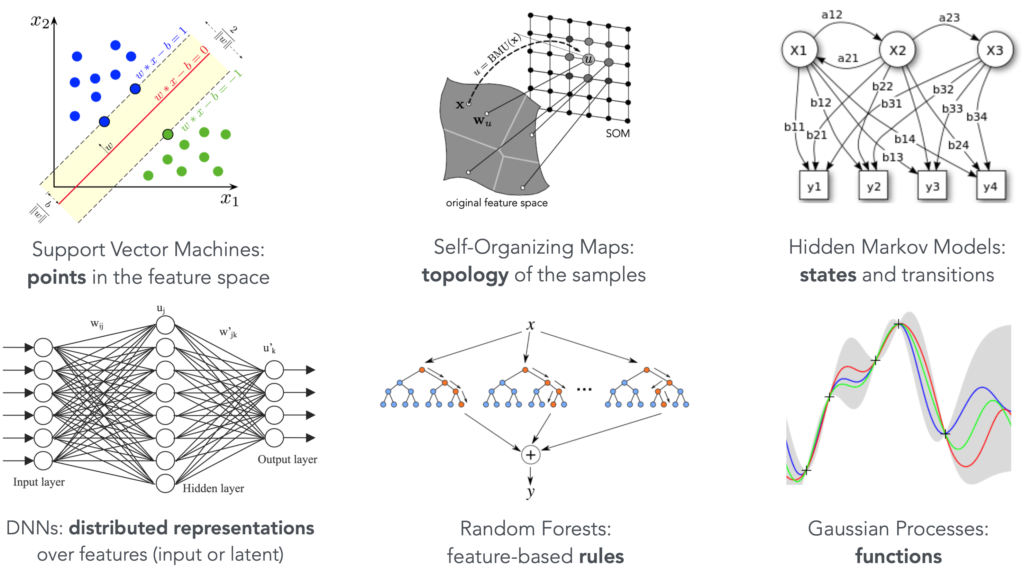
To illustrate this point let us walk thought a couple of examples from the illustration above. A model obtained with the Support Vector Machine (SVM) algorithm consists of a set of data points that happened to be the ones that define the separating hyperplane between the data classes (first image). So, for example, if what you wanted to know from your data analysis was “Which data points are on the very edge of the decision boundary?” then a model trained with SVM will naturally provide you with the answer.
Another strong case is the case of Decision Tress and Random Forests (fifth image) — the resulting decision model is a set of rules in the form of “if the feature X is greater than something then proceed along this decision path, otherwise, the other path”. A decision tree is a sequence of such rules, and given a data point all you need to do to classify it is to follow the rules that the model gives and that can be expressed plainly in human language.
So don’t discard those old classical methods just yet, maybe one of them is exactly what you need and it will work without demanding the huge amounts of data modern DNNs would make you believe you need.
References
Kuzovkin, Ilya, “Understanding information processing in human brain by interpreting machine learning models“, PhD thesis, Tartu University Press, 2020
No comments yet.